Python is easy to use to run some machine learning task. One of the simple algorithms is K-nearest neighbors (KNN). In this tutorial, let’s try out the KNN algorithm in Python using Movie catalog as a sample dataset.
Table of Contents
Packages you need in this tutorial
- pandas
- numpy
- scipy
If you don’t have the above packages in your system or virtualenv, install them first. If you want to use in the virtualenv, activate your virtualenv. (Refer to this post how to activate your virtualenv)
pip3 install pandasWhen you install pandas, numpy should be installed as a dependent package. If you don’t see numpy from your pip list, you can install numpy separately by issuing the command below
pip3 install numpyYou will also need the scipy package. Issue the following command to install the scipy package as well.
pip3 install scipySample Dataset
Go to grouplens.org and download the MovieLens 100K Dataset. We will be using this sample dataset to find the similar movie.
What is KNN (K-nearest neighbors)?
KNN (K-nearest neighbors) Algorithm
In pattern recognition, the k-nearest neighbors algorithm (k-NN) is a non-parametric method used for classification and regression.[1] In both cases, the input consists of the k closest training examples in the feature space.
The output depends on whether k-NN is used for classification or regression:
In k-NN classification, the output is a class membership. An object is classified by a plurality vote of its neighbors, with the object being assigned to the class most common among its k nearest neighbors (k is a positive integer, typically small). If k = 1, then the object is simply assigned to the class of that single nearest neighbor.
In k-NN regression, the output is the property value for the object. This value is the average of the values of k nearest neighbors.
k-NN is a type of instance-based learning, or lazy learning, where the function is only approximated locally and all computation is deferred until classification.
Both for classification and regression, a useful technique can be to assign weights to the contributions of the neighbors, so that the nearer neighbors contribute more to the average than the more distant ones. For example, a common weighting scheme consists in giving each neighbor a weight of 1/d, where d is the distance to the neighbor.[2]
The neighbors are taken from a set of objects for which the class (for k-NN classification) or the object property value (for k-NN regression) is known. This can be thought of as the training set for the algorithm, though no explicit training step is required.Excerpt from Wikipedia
A peculiarity of the k-NN algorithm is that it is sensitive to the local structure of the data.
Sample Scripts
Data Prep
Since the sample dataset is in a raw format, it needs some preparation such as normalizing it.
Load the the sample data (from u.data file). Get each movie’s rating value.
r_cols = ['user_id', 'movie_id', 'rating']
ratings = pd.read_csv('ml-100k/u.data', sep='\t', names=r_cols, usecols=range(3))
ratings.head()
movieProperties = ratings.groupby('movie_id').agg({'rating': [np.size, np.mean]})
movieProperties.head()
movieNumRatings = pd.DataFrame(movieProperties['rating']['size'])
movieNormalizedNumRatings = movieNumRatings.apply(lambda x: (x - np.min(x)) / (np.max(x) - np.min(x)))
movieNormalizedNumRatings.head()Open the movie catalog
Load the u.item which has 1000 plus movie catalogs which has genre checks. Put this movie catalogs into dictionary along with the normalized rating values .
movieDict = {}
with open(r'ml-100k/u.item', encoding="ISO-8859-1") as f:
temp = ''
for line in f:
fields = line.rstrip('\n').split('|')
movieID = int(fields[0])
name = fields[1]
genres = fields[5:25]
genres = map(int, genres)
movieDict[movieID] = (name, np.array(list(genres)), movieNormalizedNumRatings.loc[movieID].get('size'), movieProperties.loc[movieID].rating.get('mean'))
Compute the distance between two movies
Using the following formulas, we will get the distance value. Higher the number, two movies are more irrelevant. Lower the number, it is more relevant.
def ComputeDistance(a, b):
genresA = a[1]
genresB = b[1]
genreDistance = spatial.distance.cosine(genresA, genresB)
popularityA = a[2]
popularityB = b[2]
popularityDistance = abs(popularityA - popularityB)
return genreDistance + popularityDistanceFor example, running this function with following movies:
- GoldenEye (1995)
- Exotica (1994)
It returns a compute distance of 1.1786941580756014. This means, these two movies are far from each other in terms of relevancy.
On the other hand, if you compare the below two movies, the compute distance is significantly lower at 0.010309278350515455. You can tell because below two movies have similarity in its genre.
- GoldenEye (1995)
- Con Air (1997)
Get the neighboring movies
Using the ComputeDistance function, below function will get the similar movies.
def getNeighbors(movieID, K):
distances = []
for movie in movieDict:
if (movie != movieID):
dist = ComputeDistance(movieDict[movieID], movieDict[movie])
distances.append((movie, dist))
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(K):
neighbors.append((distances[x][0], distances[x][1]))
return neighborsAssemble the code together
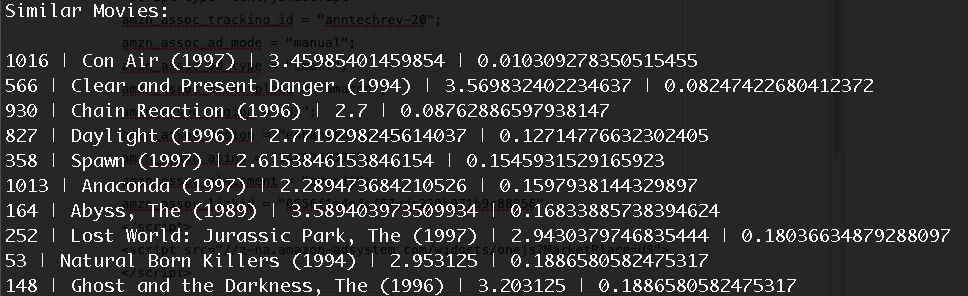
Finally, when you assemble the code together, you will get the top 10 movies similar to GoldenEye (1995) (in this example). It will look like below:
From left to right: movie ID | title | rating | compute distance
Sample Code
Download the Sample Code + Sample Dataset here.
If you want to learn more about Data Science in Python, check out the below book from Amazon.
Latest Posts
- How to convert MD (markdown) file to PDF using Pandoc on macOS Ventura 13
- How to make MD (markdown) document
- How to Install Docker Desktop on mac M1 chip (Apple chip) macOS 12 Monterey
- How to install MySQL Workbench on macOS 12 Monterey mac M1 (2021)
- How to install MySQL Community Server on macOS 12 Monterey (2021)